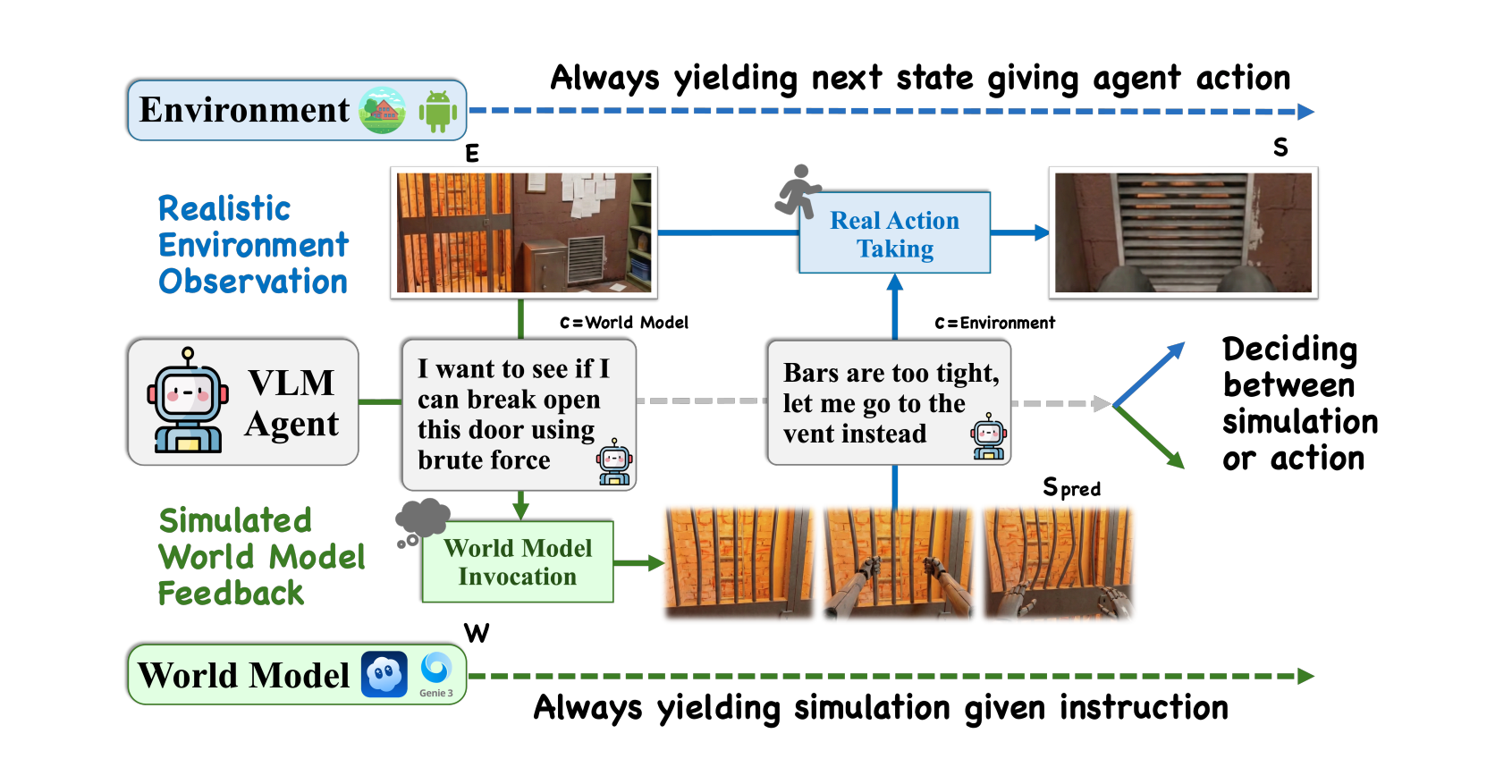
Foresight
Available.
Foresight Unused.
Available.
Foresight Unused.
We give agents access to state-of-the-art generative world models. They almost never use them. And when they do, the results are often worse than acting blindly. This paper dissects why — and charts a path forward.