User-First.
Multi-Turn.
RL-Trained.
Multi-Turn.
RL-Trained.
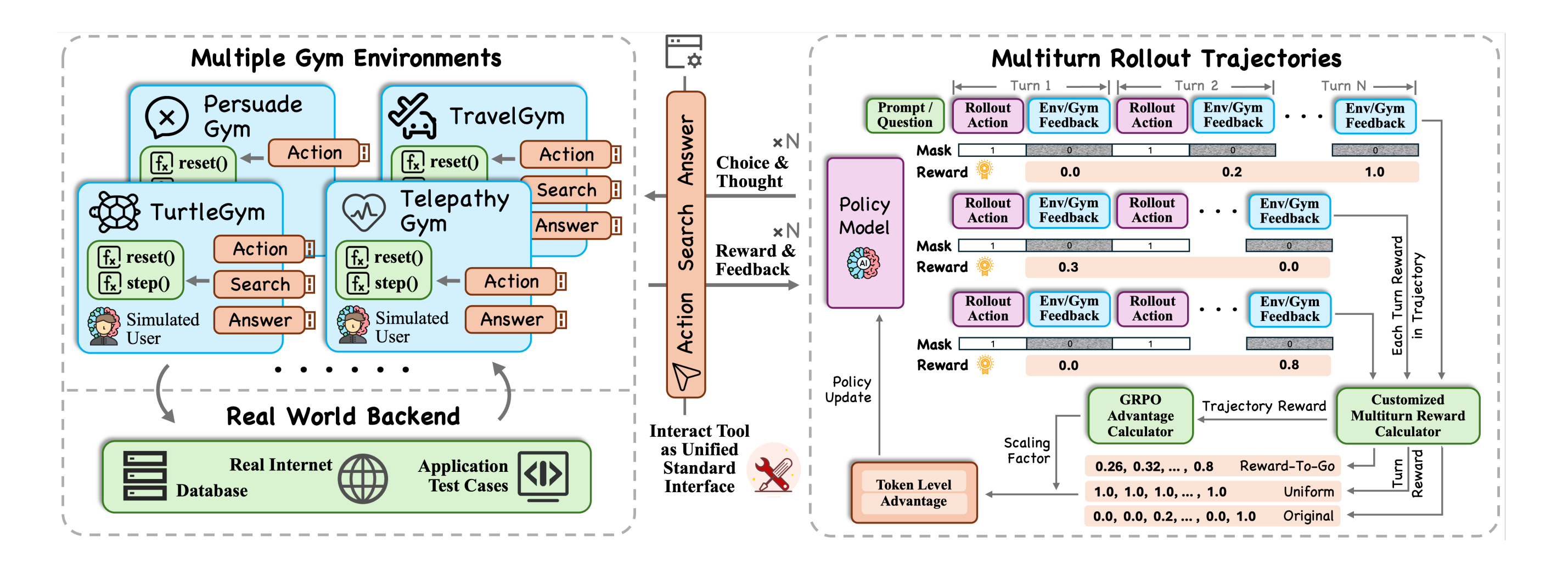
Most RL agents are trained to complete tasks — not to satisfy users. UserRL bridges this gap by pairing standardized gym environments with simulated users, training agents that can handle diverse, dynamic, multi-turn interactions via GRPO — unlocking SFT cold-start critical capabilities and deliberate trajectory scoring.