Fine-Grained
Rewards.
Real-World Tools.
Rewards.
Real-World Tools.
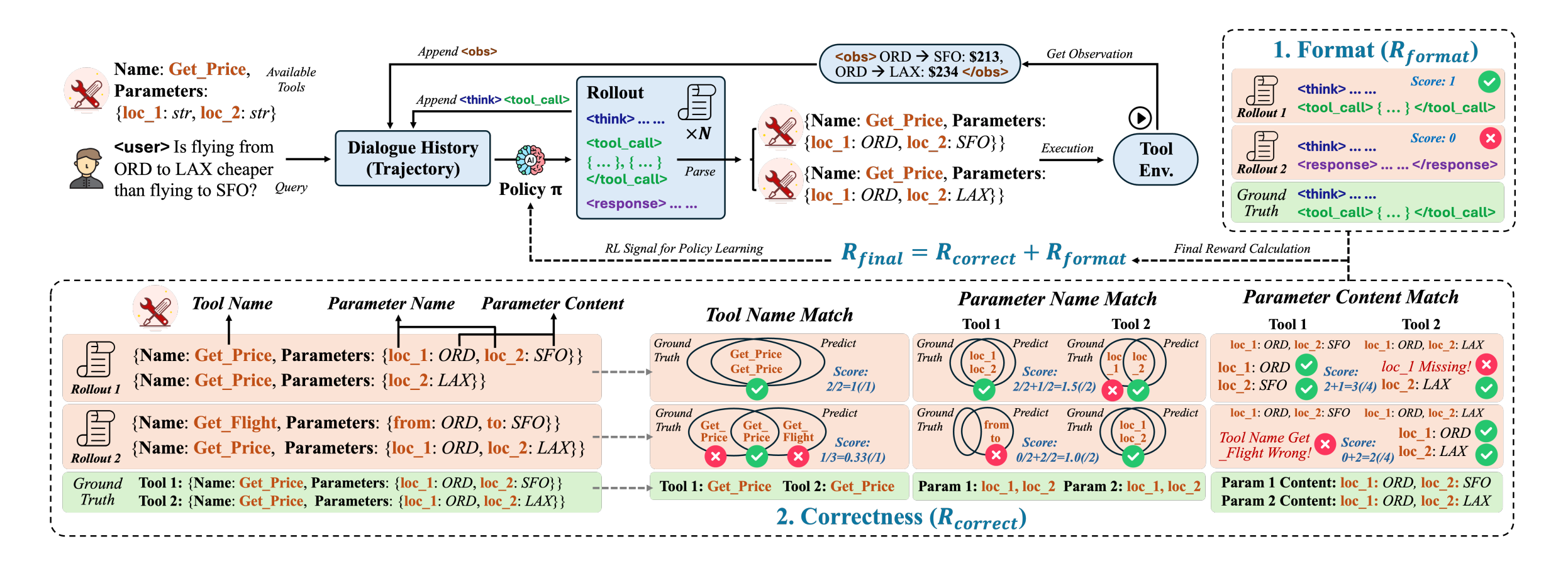
SFT-trained tool agents imitate trajectories but fail to reason about tools. ToolRL trains LLMs with RL from scratch using a principled, multi-level reward that scores tool name selection, parameter schemas, and parameter values — leading to 17% gains over base models and 15% gains over SFT.