Strategic.
Self-Aware.
Efficient.
Self-Aware.
Efficient.
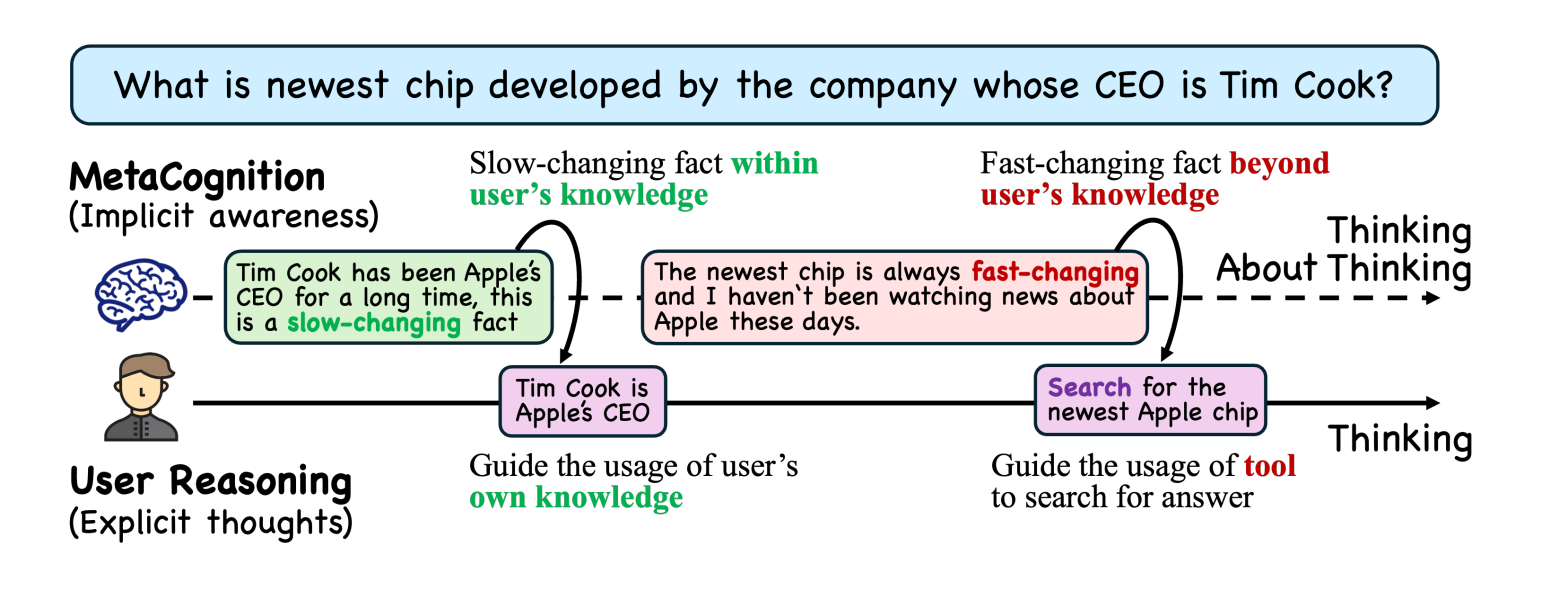
LLMs unnecessarily invoke tools over 30% of the time — even for tasks their own knowledge handles perfectly. SMART instills metacognitive awareness so agents know when tools help and when they don't.